| Modularity of Mind | |
|
|
|
|
Introduction |
|
|
Cognitive Science is distinguished from other approaches to the study of the mind by the fact that it restricts itself to explanations in terms of information processing. One of the fundamental points of interest in cognitive science has been the type of mental structure that is appropriate to a description of the information processors involved. I’ll present several popular varieties of mental structure later by way of setting the scene, but the one that I’m going to be arguing for today is known as the modular theory of mind. Just so that you know what to expect, I’m going to defend an idea that naturally leads to the view of the mind described by Pinker in his popular book ‘How the Mind Works’. He says[1]:
The mind is a system of organs of computation, designed by natural selection to solve the kinds of problems our ancestors faced …
Now, this is a more generalised view than the one we’ll be dealing with, but the picture of the mind it suggests as a device constructed out of many other simpler devices should be familiar to you from our earlier discussions of functionalist architectures and Dennettian disappearing homunculi. Think again of those levels of cooperating homunculi, each level containing homunculi performing their functions by the combination of functions of simpler homunculi below them, extending from the very dumbest levels to levels where their behaviour has all the appearance of intelligence. The ‘organs’ that Pinker is talking about may be any (evolutionarily) reasonable subset of those homunculi, but we’ll begin by talking about ‘modules’ which characteristically include devices at the very dumbest levels bringing in data from the world, which follow the chains of increasing complexity of function fairly strictly, and which have a pretty well-defined end point.
I’m going to start, however, by describing one particular function of the mind, which I’ll be using as an example thereafter. It will turn out to be a paradigm case of modularity. [1] S. Pinker, How the Mind Works, (London: Allen Lane, 1997) p. 21.
|
|
|
Vision |
|
|
The most obvious information processing capability of our minds is the ability to interpret visual data. It is also an extremely difficult problem, as scientists working on artificial vision projects have discovered. In fact, it is an impossible problem. There is actually no unique answer to how we should interpret the visual stimuli that impinge upon our visual sense organs. Just consider what evidence we have to go on when we are trying to decide what we’re looking at: in any visual sensation there are patterns of shade and light and colour, and there are slight differences in the patterns presented to each eye, and there are changes in the patterns of shade and light and colour in different experiences. It’s not hard to see that there are an endless number of different ways in which the world could cause those patterns of stimulation, so how is it that we are able to perform our interpretations so effortlessly?
We are lucky that we have the beginnings of a good theory about this now, due to David Marr.[1] According to Marr the visual processor works by gradually building up a representation of an object through several well-defined stages, operating on not much more information than mere discontinuities in light intensity on the retina. Here’s a simplified view of the stages of the process:
[Sensation] ¯ Raw primal sketch ¯ Primal sketch ¯ 2½-D sketch ¯ 3-D model ¯ [Perception]
Now let’s look at each of those steps a little bit more closely.
1. Raw Primal Sketch
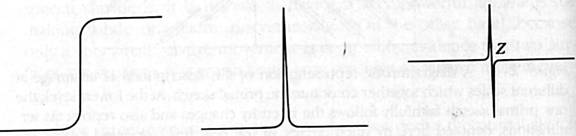
We may think of the output of the first stage of processing as a 2-dimensional sketch that uses lines and loops to indicate the existence, position, and relationships of the patterns of discontinuities in the light intensity upon the retina. Some of the most complete models have been provided for this simplest level of processing. For example, consider how we would go about identifying edges. What would the visual field look like when there is an edge to be identified? Presumably, something like this:
a a a a a a a b b b b b b b b a a a a a a a b b b b b b b b a a a a a a a b b b b b b b b a a a a a a a b b b b b b b b a a a a a a a b b b b b b b b a a a a a a a b b b b b b b b a a a a a a a a b b b b b b b a a a a a a a a a b b b b b b a a a a a a a a a a b b b b b a a a a a a a a a a a b b b b
where ‘a’ and ‘b’ stand for some values of light intensity at points of the retina. Our immediate thought is that we should try to apply some algorithm that compares neighbouring pixel values: maybe we could try subtracting left from right. That would give us a new field:
0 0 0 0 0 0 0 c 0 0 0 0 0 0 0 0 0 0 0 0 0 0 c 0 0 0 0 0 0 0 0 0 0 0 0 0 0 c 0 0 0 0 0 0 0 0 0 0 0 0 0 0 c 0 0 0 0 0 0 0 0 0 0 0 0 0 0 c 0 0 0 0 0 0 0 0 0 0 0 0 0 0 c 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 c 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 c 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 c 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 c 0 0 0
This sort of detector is called a zero-crossing detector, because of the nature of the graph of the second derivative of the change of intensity across the visual field. This sounds pretty complicated, but it’s easy to see what is meant by looking at those graphs.
[1] D. Marr, Vision (New York: W. H. Freeman, 1982).
|
|
|
(a) (b) (c) |
|
|
(a) is a graph of the intensity across the visual field. (b) is a graph of the rate of change of the graph in (a) (c) is a graph of the rate of change of the graph in (b). Note how the graph crosses the 0 line.
This looks pretty good, so all we need to do now is to convince ourselves that there is a way to implement this function in a biological system. And there is:
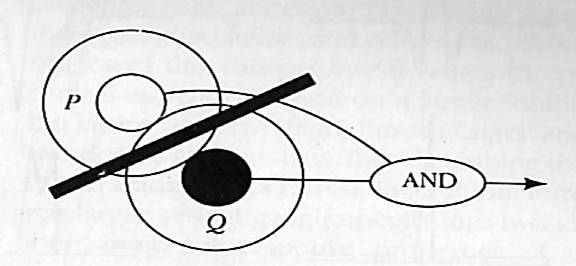
[T]he spatial organization of the receptive fields of the retinal ganglion cells is circularly symmetric, with a central excitatory region and an inhibitory surround. Some cells, called on-centre cells, are excited by a small spot of light shone on the centre of their receptive fields, and others [called off centre cells] are inhibited.[1]
Using cells like this we can make a zero-crossing detector, thus:
[1] Marr (1980) p. 64.
|
|
|
|
|
|
If P is an on-centre cell and Q is an off-centre cell, then if they are both active there must be a zero-crossing between them, so simply connect them by an AND-gate, which is active only when they’re both active, and you have the fundamentals of a detector.
2. Primal Sketch
Using data from the raw primal sketch, we derive the primal sketch. Again, this is a 2-dimensional representation of the visual field but it includes inferred information that is absent from the raw primal sketch. For example, the triangle that we see in the following figure is inferred at this stage.
3. 2½-D Sketch
Given the Primal Sketch we derive the 2½-D Sketch, which is still a viewer-centric representation of the visual field, but now also represents the distance from the viewer of each point in the field, and the orientation of the inferred surface marked by each point. Marr’s standard illustration for this is the following diagram:
This representation is constructed using the outputs of processes that take as input the changes in light intensity with time or within defined volumes of the visual field. The sort of thing that registers at this stage is the change in size of a defined volume of the field, which is generally interpreted as movement towards or away from the viewer. We see this all the time in films, and you will notice that our interpretation of what’s happening is consistently wrong when we’re watching films. The film-maker offers cues to our interpretation that are specifically designed to lead to our getting it wrong. Or imagine that I have two transparencies: one is completely covered by a random speckle pattern; the other has a sparser random speckle pattern in a smaller square area. If one is laid on the other the viewer sees only a random pattern, but if the one with the square pattern is moved, the square will be quite apparent. Marr (and others, of course) conclude that we must be applying a specific process for deriving shape information from motion information.
In fact Marr thinks that there are likely to be several processes that are responsible for each of the inferences. In the case of depth perception, for example, he identifies four different processes:
1. by comparison of the visual data from the two different eyes (which we tend to think of as the only important mechanism,) 2. alteration of the patterns of retinal activity interpreted as due to the movement of the object being viewed, 3. alteration of the patterns of retinal activity interpreted as due to the movement of the viewer, 4. interpretation of the object’s silhouette.
These processes are all quite robust and seem to operate independently: for each of them we can remove all the cues except the information that that process operates on and the inference will still go through. And note too that since we know that there are many other ways in which the same data could be caused, the fact that the processes give a unique, determinate result must mean that they are not considering all the possibilities. We conclude that there are assumptions about the world built into the processes, and that the assumptions are such that they can be wrong (as in watching a film,) but in the real world we live in will mostly be right.
4. 3-D Model
Given the 2½-D Sketch, which is still a viewer-centric representation of the visual field, we then derive the 3-D Model, which is a representation of the object independent of the viewer’s point of view. It is this representation that is the final output of the visual processes and is the last stage of reconstruction before we are able to ‘recognise’ the object. It’s only at that stage that we can really start talking about ‘perception.’ But how are we to think of such a representation? Marr proposes that it should be thought of as an articulation of generalised cones. In observing a dog, for example, we would construct a 3-D model with so many cones linked up to make each leg, a cone or two for the body and another for the head, and some long ones for the tail. This might seem a rather an odd thing to think until we consider what sort of information is supposed to be contained in this model and how little structure is actually required to contain this information. It may help also if you think of these generalised cones as just ways of talking about more abstract information in pairs of vectors, one of which indicates an axis of symmetry for the object, and the other of which indicates the radius of the object about its axis.
But even so, that’s a type of model that involves some pretty substantial assumptions about the way the world really is. It works OK because the assumption is generally correct – most of the objects that we need to recognise quickly and effortlessly are indeed rather close to articulations of such generalised cones. But this is a purely contingent thing, and if the world was otherwise, and we came into contact with cloud-like things more often and in more vital situations then our visual processors would not be appropriately tuned to the world. Presumably alien creatures that live in very alien environments would have different styles of pre-perceptual model.
|
|
|
|
|
|
Prologue: Four Historical Accounts of Mental Structure |
|
|
That’s probably enough for a description of the visual faculty. There’s plenty more to say, of course, but I just wanted to give you a taste of a theory of such a faculty. You should think of this theory when we start talking about proposed mental architectures. Now I’m going to give you the summary I promised of the various architectural types that have been proposed.
1. Functional Architecture: Horizontal
In a tradition dating back to Plato a faculty is distinguished by reference to its typical effects, and mind is analyzed into component mechanisms. The ‘horizontalist’ describes cognitive processes as distinctive combinations of the faculties which are not domain-specific. The same judgment, for example, might be exercised in perception or morality.
2. Functional Architecture: Vertical
The phrenologist Gall denied that there are any domain-independent faculties and posited rather propensities and dispositions specified both by domain and function. The psychological mechanism for each is distinct. If it were otherwise, Gall claimed in an invalid argument, that any faculty would be equally efficacious in any area, which is not the case for memory for example. Gall’s theory specified:
a. domain specificity b. genetic determination c. association with distinct brain structures d. computational autonomy
3. Associationism
Faculty psychology fell foul of Empiricism, in accord with which psychological principles were restricted to the following:
a. There is a set of atomic entities of which mental structures are composed. Reflexes for behaviourists, ideas for mentalists, etc. b. A (recursive?) relation of association is defined over these atoms. c. Laws for the application of association are defined. d. There are parameters of psychological structures by which differential efficiencies of function can be explained.
Faculties are unnecessary because all psychology is reducible according to those principles; or there is only the faculty of forming associations. This, at least, is favourable to theoretical parsimony. Another view is that faculties are structures created from elements which are themselves created by associationist processes.
However, the motivation seems originally to have been to do away with ideas of irreducible mental structure, so association should not operate via a set of mechanisms operating upon mental contents or it loses its point. Association is to be likened to gravity rather than to computation. One of the necessary hopes of associationism is to eliminate Nativism in favour of Empiricism and the internal mirroring of external relations, but as operative mental structure is enriched this project becomes less plausible. Hence we get the recent neocartesianism and its arguments from the ‘poverty of experience.’
4. Neocartesianism
Chomsky likens mental structures to physical organs, and suggests that for both ontogenetic development is the unfolding of an ‘intrinsically determined process.’ Specifically, he holds that a certain ‘body of information’ is innate. In language, it is the integration of this corpus with ‘primary linguistic data’ which explains mature linguistic ability. The integration is computational, therefore respecting semantic relations, therefore operating upon objects of propositional attitudes. The paradigm of mental structure is thus the implicational structure of semantically connected propositions.
This is more plausible for some faculties than for others. Memory is a competence which cannot derive from the cognising of propositions. It really is like a physical organ. More likely, neocartesian-type mental structure is only a special part of the faculty story.
Moreover, psychological faculties of a distinct type would be required to explain how to map propositional entailments to cognitive consequences. Such faculties could not be neocartesian.
|
|
|
Prospectus |
|
|
A taxonomy of cognitive systems needs to answer these questions:
a. Is it domain-specific? b. Is it innately specified or experientially developed? c. Is it hierarchically assembled? d. Is it hardwired? e. Is it computationally autonomous?
The concept of a cognitive module will be associated with a pattern of answers to these questions. Roughly; yes, yes, no, yes, yes. It is therefore a vertical faculty. It will be shown that:
a. Modules probably effect a particular functionally definable subset of cognitive systems. b. All other cognitive systems are a priori plausibly non-modular. c. Those systems, although interesting, are by that fact rendered obscure in principle.
|
|
|
Functional Taxonomy of Cognitive Systems |
|
|
If we think of minds as symbol-manipulating devices we may compare them to computers, but require peripheral systems called transducers (T) to interface with the world. Computation is purely syntactic so for information from these T to be processed it needs to be passed on via appropriate symbols. Manipulation of these symbols is initially confined to input systems (IS) but may finally involve central processes (CP). These three levels are not necessarily exhaustive.
T outputs represent raw stimulus data from which IS inferentially produce representations of the world. Note that the functional distinction of IS and CP is contingent and that positing it commits us to a separation of perception and cognition. Curiously, the IS for world-representation in the appropriate format for CP seem to include perception – and language. In perception we note a correspondence between proximal stimuli and distal facts; and similarly in the case of language, we note a correlation between claims about the world and facts about the world.
|
|
|
Input Systems are Modules |
|
|
1. Domain Specificity
The significant core of this idea is that there are distinct psychological mechanisms corresponding to distinct stimulus domains. Experiments at the Haskins laboratories suggest different mechanisms analyze speech and non-speech audition, the mechanisms being differentially activated by a restricted range of stimulations. Another contention is that the more eccentric a domain – the more that successful analysis requires information and processing specific to that domain – then the more plausible it is that a special-purpose device is used. Language is very eccentric, so is face-recognition, and Ullman’s experiments suggest mechanisms for recognition of 3-D forms are specialised.
2. Mandatory Operation
Interpretation of heard sentences can’t be prevented and neither can the visual interpretation of optical data as special data. Illusions persist despite our recognition of them as such.
3. Variably Accessible Representations
All IS theories propose several inferential steps; as in every transformational grammar’s move from Deep to Surface Structure, or in levels of visual interpretation. Note how details of a perception are quickly lost though they must have been significant in processing the information. Can you describe the numerals on your watch? Some levels are quite inaccessible to reporting though behaviour is sensitive to the information to be had there. Other levels can only be accessed at a price in memory or attention. Generally, accessibility increases with interpretational level and abstraction from T output.
4. Speed
Sentence comprehension demonstrated in fast shadowing is as fast as any voluntary response seen, despite the enormous amount of processing which is (supposed to be) required. With an average of 4 syllables per second in normal speech the ¼ second delay is compatible with syllabic processing; and other evidence supports the syllable as the shortest recognisable linguistic unit. Comprehension speed may therefore be near the theoretical limit.
5. Informational Encapsulation
It is theoretically possible that lower level analyses might be assisted by information feedback from higher levels; but consider illusory persistence – manipulating the eyeball will always produce inappropriate special inferences. Most sorts of feedback are incompatible with modular domain specificity. Moreover, the function needs to be performed of presenting the world as it is rather than as we expect it to be (Pylyshyn’s cognitive impenetrability of perception.) The IS must be adequate to represent novelty, therefore adequate to represent anything.
Since T outputs underdetermine IS outputs, the IS are non-deductive inferrers, therefore they project and confirm hypotheses. The confirmation function has very restricted access to represented information. This restriction may be based on a speed/accuracy/utility trade-off.
Note that computational resources are not necessarily all dedicated as Gall would have claimed. In fact performance degradation in multitasking experiments strongly suggest there may be competition between IS for workspace.
In place of explicit arguments for informational encapsulation here are some criteria for evaluation evidence brought against it:
a. The locus of the feedback must be internal to the IS. Eventually the IS products will be used by the CP and at that stage there will certainly be anti-hierarchical processes. The boundaries of the stages must be shown to have been breached; therefore the boundaries need to be defined. b. Output of some non-IS processing may be at the same level as some IS output. Evidence of feedback in the former does not imply feedback in the latter. For example, comprehension of noisy linguistic data via context-driven expectations (Cloze values) is highly attentional and cognitive and is clearly non-modular. c. Feedback within IS is not denied. For example, if phoneme restoration is context-driven then encapsulation is contradicted, but not if it is vocabulary-driven. Moreover, modular processes might improve efficiency by mimicking feedback; as in the proposal that purely lexical associationism may be capable of substituting for context analysis.
6. Output Shallowness
The more constrained the information the IS can encode, the more plausible is its encapsulation. We expect to be able to ‘directly see’ colours but not proton tracks. We must ask what properties relevant to the encoding of a percept could be made available by a system which was fast, mandatory, and encapsulated. For language, linguistic form is a possibility, especially since context does not determine form and feedback is therefore unhelpful. So is definition recovery, though experiments do not support the latter. (That IS appear to pick out phenomenal features constituting Natural Kinds is a support for the thesis that IS are themselves Natural Kinds – ie. real.)
Some levels of abstraction have greater psychological salience. Consider the hierarchy poodle-dog-animal-thing which is in some sense ordered by implication. Dog seems central and constitutes a basic category (BC). The idea is hazy but BC are associated with the satisfaction of the following set of psychological properties:
a. High frequency of the word for the BC (WBC). b. WBC is learned earlier. c. WBC is least abstract single syllable in hierarchy. d. BC are apt for ostensive definitions: as in, ‘Lo! A dog.’ e. BC are apt for associations. f. BC are preferred levels of description. g. BC are preferred conceptualisations, phenomenological givens. h. You can draw ‘just a dog’ but not ‘just an animal.’
BC are candidates for the most abstract members of their hierarchies which could be assigned by IS.
7. Neural Dedication
All massive neural structures whose cognitive functions are known appear to be input analyzers. Encapsulation is to be expected as hardwiring would facilitate information flow where it is needed, but restrict it elsewhere. This also implies IS are Natural Kinds.
8. Characteristic Malfunctions
The malfunctions of IS are inexplicable as degradations of global capacities. However, any functional system may be selectively impaired so this is not a strong argument.
9. Characteristic Ontogeny
The development of both language and visualization appear to be largely endogenously determined, sensitive to the maturity of the subject rather than its environment.
|
|
|
Central Systems |
|
|
1. Necessary Properties of CP
There have to be systems which are not domain-specific so that the various IS can be interfaced. Consider:
a. Mechanisms to fix perceptual belief should integrate as much as possible of the store of information; certainly more that is available to any IS. b. We have to be able to say what we see. c. There has to be an interface between perception and utilities which protection of veridicality by impenetrability makes impossible in IS.
Promiscuity alone does not mandate non-modularity; a further need is unencapsulation. Lacking direct evidence we shall simply claim the plausibility of an analogy with the better known (and successful) non-demonstrative belief fixation of Science. That is typically unencapsulated, being isotropic (I) and quinean (Q) (both ‘fodorisms’.) We shall now consider these properties.
a. Isotropy
Facts relevant to the confirmation of an hypothesis may be drawn from any area of empirical or demonstrative truth. This is reasonable for any project, whether scientific or cognitive, whose purpose is to establish the truth about things of which we are ignorant.
(Actually analogical reasoning like this is itself a pretty fair example of I. It is striking how important analogy seems to be in many higher cognitive functions without there being even a poor theory of its operation. This obscurity may be a necessary consequence of the global nature of analogic.)
b. Quineanism
The degree of confirmation for any hypothesis is dependent upon the entire belief system. Discriminatory criteria such as simplicity, conservatism, etc. are properties relative only to the entire system.
2. Plausible Non-Modularity of CP
It now has to be shown that such properties are incompatible with modularity and that they plausibly belong to the CP. As motivation, note that there is neurological support for global processing. On the IS/CP model mooted, IS would be evidenced by stable architecture and CP by unstable connectivity; and this does seem to be what we find.
It is pretty obvious that systems are non-modular in so far as they are I/Q, since I requires that a confirmation procedure have access to all domains, and Q properties like simplicity are only really plausible if they apply to the totality rather than a subset of beliefs.
Encouragingly, the sorts of problems which arise in constructing theories of CP are what we would expect if CP were I/Q. For example, the Frame Problem – that there seems to be no principled way to delimit (frame) the information that can affect or be affected by any particular problem-solving and that which is irrelevant to it. No local solution is likely since:
a. no restricted set of beliefs can be isolated as ‘possibly affected by an action;’ b. the consequences of a new belief are not signalled in that belief; c. the set of beliefs apt for reconsideration is not definable.
The problem is most pressing in accounting for non-demonstrative consequences.
The general response in AI is to propose that in principle belief fixation is I/Q yet, in practice, for any problem set there are heuristic processes which have localised scope. It has been proposed that a collection of such heuristics could possess our own level of I/Q; however, recent attempts in A/I (frames) resort to cross-referencing which is not constrained in principle – thus recreating the problem.
|
|
|
Concluding Remarks |
|
|
1. On Epistemic Boundedness
If all cognition was modular then, unlike general systems, we could only consider problems for which we were specifically designed. This is the problem of epistemic boundedness. The IS/CP structure avoids this, but epistemic unboundedness is incoherent anyway. Consider that any hypothesis forming and confirming system requires:
a. a source of hypotheses b. a database c. a confirmation metric for hypotheses wrt databases
Such a system may fail to pick the best hypotheses because of bad design. Even if it is non-modular the source of hypotheses may be insufficiently productive. Note that we don’t doubt that this is true for non-humans – science is not open to spider, and maybe not to us.
2. On Opacity of the CP
We can define these taxonomies of cognition:
a. Functional: input analyses vs. belief fixation. b. Subjective: domain specific vs. domain neutral. c. Computational encapsulated vs. I/Q. d. Architectural stable vs. volatile connectivity.
If the IS/CP proposal holds then they are coextensive. They also happen to distinguish areas of cognitive science which are respectively productive and mysterious.
The difficulties should not be surprising because:
a. there is no gross structure to give science a point of departure by matching form and function, b. there are no divisions in the phenomenon by which the whole may be known by its parts, our typical strategy.
3. Reasons to Prefer the Modular Theory
There are good reasons to think that something like modularity of mind is an appropriate cognitive architecture.
a. To begin with, we think that we have examples of just this sort of module. I have introduced you to the vision faculty, and have alluded also to the language faculty. That has often been taken as a paradigm case of modularity – despite the fact that Chomsky seems rather to prefer the ‘organ’ model. b. The architecture is apt for evolutionary development and modification. It is much more easily conceivable that functions should be developed independently and perfected in gradual stages, than that they should be developed in one large holistic mass. In the latter case one can neer be quite sure where to begin debugging. Compare the functionality of Unix systems versus Microsoft. Compare the NZ Post Office or Housing Corporation pre- and post- the 1984 Labour government reforms. It is a very general fact.
|
|